









АэЗСДы ЛъЧаЧљЗТДмРК ‘2022Гт РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭ БИУрЛчОї’ПЁ МБСЄЕЦРИИч, ‘РЧЗс·Й§Зќ РќЙЎМРћ ИЛЙЖФЁ ЕЅРЬХЭ БИУр’ КаОпИІ ИУАд ЕЦДйАэ ЙрЧћДй. АњЧаБтМњСЄКИХыНХКЮАЁ СжАќЧЯАэ, ЧбБЙСіДЩСЄКИЛчШИСјШяПјРЬ УпСјЧЯДТ ЛчОїРЬДй.
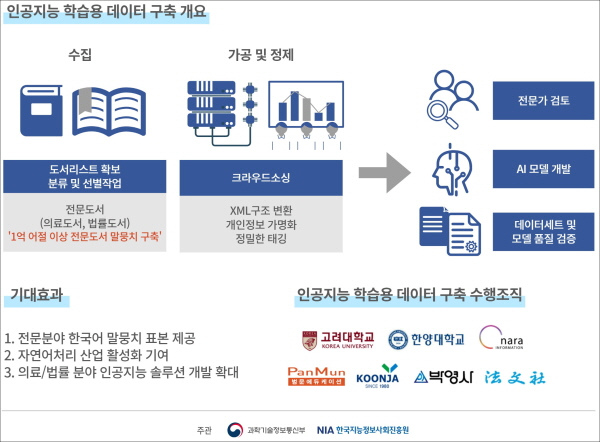
АэЗСДы ЛъЧаЧљЗТДмРК РќЙЎСіНФРЬ ЧЪПфЧб РЧЗс Йз Й§Зќ КаОпРЧ ИЛЙЖФЁИІ УМАшРћРИЗЮ КаЗљЧи АэКЮАЁАЁФЁ ИЛЙЖФЁ ЕЅРЬХЭИІ БИУрЧЯАд ЕШДй. ИЛЙЖФЁ(ФкЦлНК corpus)ДТ ФФЧЛХЭЗЮ АЁАј-УГИЎ-КаМЎЧв Мі РжЕЕЗЯ РњРхЕШ О№ОюРЧ РкЗсИІ ИЛЧбДй.
РЧЗсПЭ Й§Зќ РќЙЎЕЕМ АЂ 200СОРЛ МБСЄЧи 1Оя ОюР§ РЬЛѓРЧ СЄСІЕШ ИЛЙЖФЁИІ БИУрЧЯДТ АЭРЛ ИёЧЅЗЮ ЧЯАэ РжДй. РЬИІ РЇЧи УжНХ РќЙЎЕЕМРЧ Е№СіХа ЦФРЯРЛ МіС§ЧЯАэ, РЧЗс·Й§Зќ·О№Ою КаОп РќЙЎАЁПЭ ЧдВВ ХЉЖѓПьЕх ПіФП(РлОї ТќПЉРк)ИІ БИМКЧбДй. КИДй СЄЙаЧЯАд ЖѓКЇИЕЕШ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭММЦЎИІ СІАјЧв ПЙСЄРЬДй.
РЬЙј ЛчОї УпСјРЛ РЇЧи АэЗСДы ЛъЧаЧљЗТДмРК 6АГ БтАќАњ ФСМвНУОіРЛ БИМКЧпДй. БКРкУтЦЧЛч, ЙкПЕЛч, ЙќЙЎПЁЕрФЩРЬМЧ, Й§ЙЎЛч Ею РЧЗс Йз Й§ЗќКаОп РќЙЎ УтЦЧОїУМ 4АГПЭ ЕЅРЬХЭ ЧАСњ АќИЎ ОїУМРЮ ГЊЖѓСіНФСЄКИ, ЧаНРИ№ЕЈ АГЙп Йз ЦђАЁИІ МіЧрЧв ЧбОчДы ЛъЧаЧљЗТДм ЕюРЬДй.
ЛчОїРК ПУЧи 12ПљБюСі 7АГПљАЃ МіЧрЧбДй. ЛчОїКёДТ СЄКЮУтПЌБн 20ОяПј, ЙЮАЃКЮДуБн 2Оя4250ИИПјРИЗЮ Уб 22Оя4250ИИПјРЬДй.
ФСМвНУОі РЬПм БтАќ Йз БтОїАњЕЕ ЧљОїРЛ АшШЙЧЯАэ РжДй. БИУрАњСЄПЁМДТ ПЌБИМв, УтЦЧЛч Йз AI НКХИЦЎОїРЬ ТќПЉЧЯДТ ПЌЧеЦїЗГРЛ БИМКЧи РЧЗс Йз Й§Зќ КаОпРЧ РкПЌОю УГИЎ БтМњРЛ АГЙпЧв ПЙСЄРЬДй. AI РќЙЎБтОїРЮ НЩНЩРЬ, ПЄЙкНК, ЙйРЬФЎПЁРЬОЦРЬПЭЕЕ ПЌАшЧи РЮАјСіДЩ АГЙпПЁ ЧЪПфЧб БтЙн ЕЅРЬХЭЗЮ СіПјЧв АшШЙРЬДй.
РЬЙј ЛчОїРЧ УбА§ УЅРгРкДТ БзЕПОШ РЧЗсКаОп ИЛЙЖФЁ ЕЅРЬХЭММЦЎ ЧЅСи Йз РкПЌОю УГИЎ БтМњ АГЙпРЛ МБЕЕЧиПТ АэЗСДы ОШОЯКДПј МјШЏБтГЛАњ СжЧќСи БГМіАЁ ИУОвДй.
СжЧќСи БГМіДТ “АэЧАСњРЧ ИЛЙЖФЁДТ РЮАјСіДЩРЧ ШАПыРЛ БиДыШЧв Мі РжДТ АЁРх СпПфЧб БтЙн Сп ЧЯГЊ”ЖѓИщМ “ГєРК СЄШЎЕЕПЭ РќЙЎМКРЬ ПфБИЕЧДТ РЧЧаАњ Й§Зќ КаОпПЁМ АэЕЕЗЮ СЄСІЕШ ИЛЙЖФЁИІ БИУрЧдРИЗЮНс ДйОчЧб РЮАјСіДЩ МжЗчМЧРЬ АГЙпЕЩ Мі РжДТ АшБтАЁ ЕЩ АЭРИЗЮ БтДыЧбДй”Аэ ЙрЧћДй.
.gif)

